はじめに
こんにちは。弥生株式会社でエンジニアをしています、田邊です。
先日03/28(木)に弥生で「インフラ構築、どうしてる? ~IaCの知見共有会~」という社外勉強会イベントを実施しました。

こちらのイベントでは、普段からIaC(Infrastructure as Code)でインフラ構築しているエンジニアに登壇してもらい、LTで知見を共有してもらいました。
また、後半はLTで登壇したメンバーに再び登壇してもらい、パネルディスカッションの形で、IaCについて用意したテーマについて語ったり、本番中に参加者から寄せられた質問に回答したりしました。
このイベントは非常に好評で、90人枠で開催したものの、申込者が多く、最終的には132名の方に申し込みいただきました。
弥生では「もくテク」というイベント名でこのような社外勉強会を不定期で8年近く開催しているのですが、これまでのイベントで2番目に多い動員数となりました。
このイベントはconnpassという主にIT勉強会のイベント開催・参加ができるサイトで参加者を募集しているのですが、そのconnpassでのイベントランキングにも一時37位にランクインしました。

私はこちらのイベントの企画・イベント司会・LT登壇・パネルディスカッション司会を担当していました。 今回のブログでは、大変盛況だったこのイベント舞台裏の準備の様子をお伝えし、イベントを開催しようと考えている方の何かしらの参考になればと思います。 後半ではイベントの内容やLT資料も紹介しますので、当日参加したけれどもう一度見返したい、当日参加できなかったのでイベントの内容や発表の内容を知りたいという方はぜひこちらをチェックください。
イベント準備
開催のきっかけ
ある日の社内でのインフラエンジニアの共有会で「IaC」がテーマになりました。普段私は共有会には参加していなかったのですが、CDKを業務で使っていて興味があったので飛び入り参加しました。
自分もCDKを使っていて悩みながら実装・運用を進めていたのですが、そこで話をする中で、各チームでも悩みがありつつもそれぞれが色々な知見を持っていることが分かりました。
せっかくなのでその知見を共有するような場を作りたいと考え、イベントを開催することにしました。
登壇者集め
CDKを業務で使っている人に登壇してもらいたかったのですが、現状弥生では自分のチームメンバーやチーム外の知り合いでは限界があります。
チーム外の知り合いに、自分のチームメンバーに打診してもらうなど、色々な人の伝手を頼りながら登壇者を探しました。
快く引き受けてくれる方が多くいたおかげで登壇者を集めることができました。ほとんど初めましての方もいましたが、広く知見を共有してもらうためにも、少しコミュニケーションを頑張って自分が普段関わらないチームのメンバーにも声をかけることができたのは良かったと思います。
イベント準備
「もくテク」というイベントは、不定期ではありつつも何度も開催しているイベントなので、社内の知見が多く溜まっていました。社内のもくテクの運営のメンバーに協力いただいたことで、Zoom等の企画内容にかかわらない準備について大きく困ることはありませんでした。
これからイベントを開催しようとしている人にとっては強くてニューゲーム的な参考にならない話ですみません。機会があれば弥生のイベント運営のしかたについても今後もしかしたら改めてご紹介するかもしれません。
イベントページ公開・X投稿
イベントページを準備し、connpassで公開しました。イベントページを作る際は「どういう人がターゲットなのか」「このイベントに参加すると何が得られるのか」が伝わるようにすることを心掛けました。
開催側としては大事なイベントですが、参加者からすれば有象無象のイベントの一つなので、興味がある人にはちゃんと伝わるように工夫しました。
今回は技術系の話の中でもややコアな話(全くの初心者では分からない話)なので、興味を持ってもらうことよりも伝えることを意識しました。
また、X(旧Twitter)で、弊社のエンジニア情報アカウント(@yayoikk_dd)を使い、開催の1週間前からLT登壇者一人一人の登壇コメントを投稿するという企画も行いました。
投稿から申し込みに結びついた方がどれくらいいるかは測定できていませんが、投稿からページのリンクに飛んでいる方は少なからずいたので、そこから興味を持ってくれた方もいたかもしれません。
LT準備
LTについては内容は特に指定せず、「IaCに絡む話ならなんでもOK」として登壇者にお任せしました。今回のイベントの開催の目的やターゲット層などを事前に共有することで最低限内容がブレないようにしました。その結果IaCの事例だけでなく「IaCが無い状態だとこうなる」という内容のLTをしてくれた方がいたり、初心者向けの話をする人がいれば経験者向けの話をする人もいたりと、LTに多様性が出たと思いました。
LTの内容の確認については、必須とすると各自早めに完成させなければならず、作る側も確認する側も負担が大きくなるので、登壇者を信用して当日までに準備しておいてくださいという形で依頼しました。
もちろん確認した方が色々準備しやすいのは間違いないですし、企画側としては確認したい部分もありますが、事前確認が無くてもできないことはないという実感はありました。
パネルディスカッション準備
パネルディスカッションの司会は私は初めてでしたが、パネルディスカッションについても入念な準備は行いませんでした。
誰が何を話すか決まっている状態だと予定調和でつまらなくなってしまうので、あまり事前の打ち合わせはせず、どんなテーマだけ話すか共有して、あとは当日に話したい人が話してもらうという形式を取りました。
打ち合わせをしなかったことで生で話す盛り上がりは出せたと思いますが、ファシリテートをしていた私としては誰がどんなことを話したいのか分かっていないので、誰に話を振るか悩ましい部分もありました。
打ち合わせはしなくとも、事前にテーマごとにどんな話をしようと思っているか登壇者に教えてもらい、それをベースにファシリテート側でどんな形で進めるか検討しておくなどが良いかもしれません。
イベントの様子
LT
LT①「CDKでの自動構築が超簡単で感動した話(超初心者向け)」
CDKを始めて間もない(3カ月)状態の立場から、CDKを使ってどんな良い点があったのかを紹介してもらいました。
やってみないと分からない部分もあるので、使ってみた実感としての良かった部分はIaCを導入するか悩んでいる人にとって参考になる部分も多かったのではないでしょうか。
スライド資料はこちら
LT②「IaCがない環境でインフラ担当じゃない人がAWS触ってみた話」
IaC回であえてIaCを使っていなかった時の運用の話をしてもらいました。
インフラ構築を手動でやるとどういう辛さがあるのか語ってもらったことで、IaCのメリットについて考えるきっかけになったと思います。
スライド資料はこちら
LT③「CDKの実装のススメ方」
CDKの実装をどう進めるのが効率が良いかについての話をしてもらいました。
初心者は公式ドキュメントをちゃんと読まないと実装を進めにくい性質上、どうすれば実装しやすくなるかという観点は貴重なものだったと思います。
スライド資料はこちら
LT④「先人の教えに背いてCDKのスタックを分割した男の末路」
CDKで重要な概念であるスタックを分割するかどうかについてのLTでした(発表者は私です)。
スタックを分割したことで生じた問題点について語ることで、今後IaCを導入する人に同じ辛さを味わってもらいたくないという想いで話しました。
スライド資料はこちら
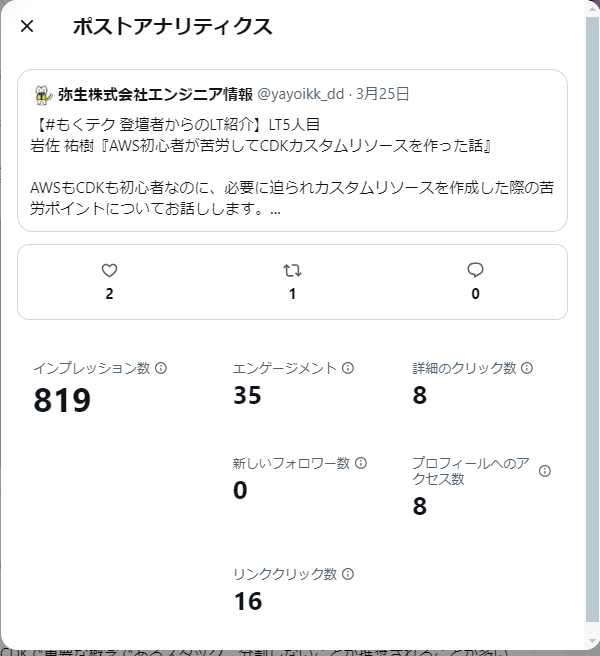
LT⑤「AWS初心者が苦労してCDKカスタムリソースを作った話」
CDKのカスタムリソースを使った感想について共有してもらいました。
初心者としてはなかなか扱いづらいポイントがあるという点は触ってみないと分からないので、業務で使った立場から話してもらえたのはとてもよいと思いました。
スライド資料はこちら
LT⑥「AWS CDK 経験者が CDK for Terraform 使ってみた」
CDK for Terraformを使って良かった点・苦労した点を話してもらいました。
苦労する部分はありつつも、CDKでの辛い部分を回避できる点があるなど、良い点も知ることができる発表でした。
スライド資料はこちら
LT⑦「Terraform v1.7のTest mocking機能の紹介」
TerraformのTest mockingの機能の紹介をしてもらいました。
知らなかった機能を知れるという観点に加え、こういった新機能の良い点・悪い点を実際に使った立場から語ってもらえてよかったです。
スライド資料はこちら
パネルディスカッション
パネルディスカッションでは「IaCの辛い部分」や「IaCをあえて使わずに構築するケース」などのテーマを基に登壇者に自由に話してもらいました。
また、Zoomの視聴者の皆さんからのコメントでの質問やXでの投稿から「こういうケースはどうしているか」「この機能は何か活用しているか」などの質問も多くいただき、それについても答えることができました。
LTだとどうしても一方的に話すことになるケースがありますが、パネルディスカッションをしたことで参加者の皆さんと双方向の会話をすることができ、視聴者の方々の満足度も上がったのではないかと思います。
さいごに
今回のブログでは「インフラ構築、どうしてる? ~IaCの知見共有会~」の準備の裏側の紹介と、イベントの様子の紹介をしました。
今回はこれまでのもくテクイベントと比較して多くの方々に参加してもらうことができました。
今回はある程度インフラの知識を前提としたイベントということもあり、どれくらいの人数になるのか不安もありましたが、ある程度の知識が前提となっていたことで、興味範囲が被る方から参加申し込みをしてもらえたのではないかと思います。
もくテクは今後も開催しますので、興味がある方はぜひ↓のconnpassのページから今後のイベント予告を楽しみにお待ちください。
一緒に働く仲間を募集しています
弥生では一緒に働く仲間を募集しています。 ぜひエントリーお待ちしております。