こんにちは、弥生でQAエンジニア兼スクラムマスターをしている、カトです。Women in Agile Japan 開催のWomen in Agile Tokyo 2024にオンサイト参加してきました。www.wiajapan.org
「Women in Agile Tokyo 2024に参加」で1記事にしようと思ったのですが、いろいろと書きたいことが出てきたので、記事を分けることにしました。tech-blog.yayoi-kk.co.jp
開催前日は雪でオンライン参加にするか迷うほど
会場
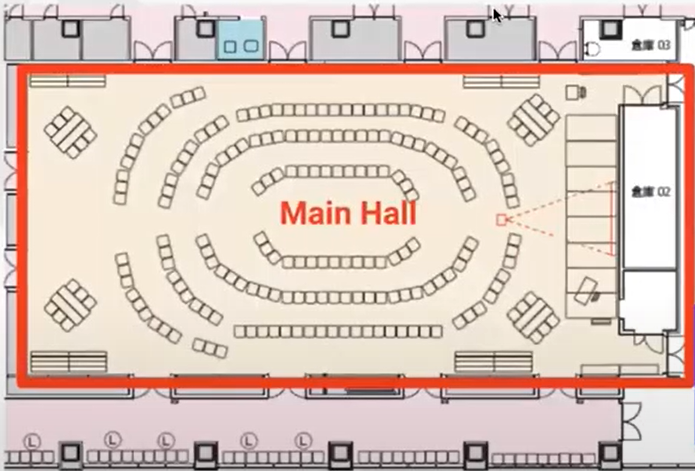
会場に到着して最初にびっくりしたのは、椅子の配置でした。メインホールの椅子の配置図 Women in Agile Tokyo 2024 Opening, Keynote & OST - YouTube より。あまりにびっくりしたのと、すでに座っている人がいらっしゃったので写真はなし。
Keynote
1.5時間ほどの講演の中で、3つのミニワーク(参加者が考える時間)がありました。
これから動画を見たり話しを聞く人にネタバレにならないように書きます。
お父さんとお子さんがお出かけ中に事故にあったシチュエーション
靴ひもを結ぶ
バスケットボールのパスをカウントする
3つともはじめて聞いたり見たりする内容でしたが、私は1つ目と3つ目はどちらも解答にたどりつきました。
開発レベル
2つ目のワーク、「靴ひもを結ぶ」ワークについてです。
弥生では、SLⅡ(セルフリーダーシップ)をもとに、会話をしています。www.blanchardjapan.jp
「"開発レベル"は人につくものではなく、タスクにつくもの」と常々意識して業務をしています。「タスク-1については"D1"だから"S1"でサポートする、一方で別のタスク-2については、"D4"だから"S4"でサポートする」というような会話がなされています。
みんなのバイアス
3つ目のワーク、「バスケットボールのパスをカウントする」ワークについてです。
私は、パスの回数を2回ほど少なくカウントしてしまっていましたが、動画を見ているときに本題となる事柄には気づいていました。
読み手に考えてもらう手順書
ワークではなく、Keynote後半でのお子さまのテニスのコーチングの話題についてです。
テスト環境独自の設定については対外資料にはないので記載する
どのような機能を持っているのかについては記載する
画面に則って進めればよいことは手順を記載しない
レビュー指摘の「記載を削りすぎてしまっていて、他の資料を見ないと操作を進められない」を反映したり、細かく書きすぎている点を調整したりと、まだ試行錯誤中です。
OST
QAエンジニア
私はQAエンジニアとしてスクラムチームでどのように立ち回ればよいのか、チームはQAエンジニアに何を望んでいるのかということを聞いてみたいと思って、「プロダクトオーナー、スクラムマスター、開発者以外のロールでスクラムで活躍するには?」というテーマだしをしてみました。
スクラムチームでのQAエンジニア活躍について考えたイーゼルパッド
まとめ
「Women」とタイトルにつく会で、Womenや多様性について考えることはもちろん、コーチングや自分の業務についてふりかえり、考えるきっかけにもなる会でした。
さて、私は次回何色の髪で参加するのでしょうか?
最強ピンクになれるよう、日々精進してまいります。
弥生では一緒に働く仲間を募集しています。
ぜひエントリーお待ちしております。
herp.careers